230519_-1_进度搬运_第1个AI项目_珂朵莉So-Vits模型
本篇内容搬运自hugeface
仅用于存档和记录学习进度,若有视频(及其截屏),请以空间为准
记录时间:2023年05月19日
https://huggingface.co/overload7015/So-Vits-SukaSuka-Chtholly
很久之前玩AI模型的时候做的,现在因为毕业之后找工作压力太大,已经很久没玩了。
珂朵莉So-VITS模型实验总结
实验目标
在60%的情况下,通过入门级发烧HiFi设备无法分辨模型生成的声音与人类声音的区别。
实验结果
- 炼制了两个版本:
- 通用版(80800Step):追求声线相似性,适合大多数场景。
- 特殊版(21600Step):增强高音域适应性,适用于特殊场景。
- 通用版声纹相似度达99.9%,建议优先使用。
- 中文、日文、英文效果评分分别为7/10、9/10、7/10。
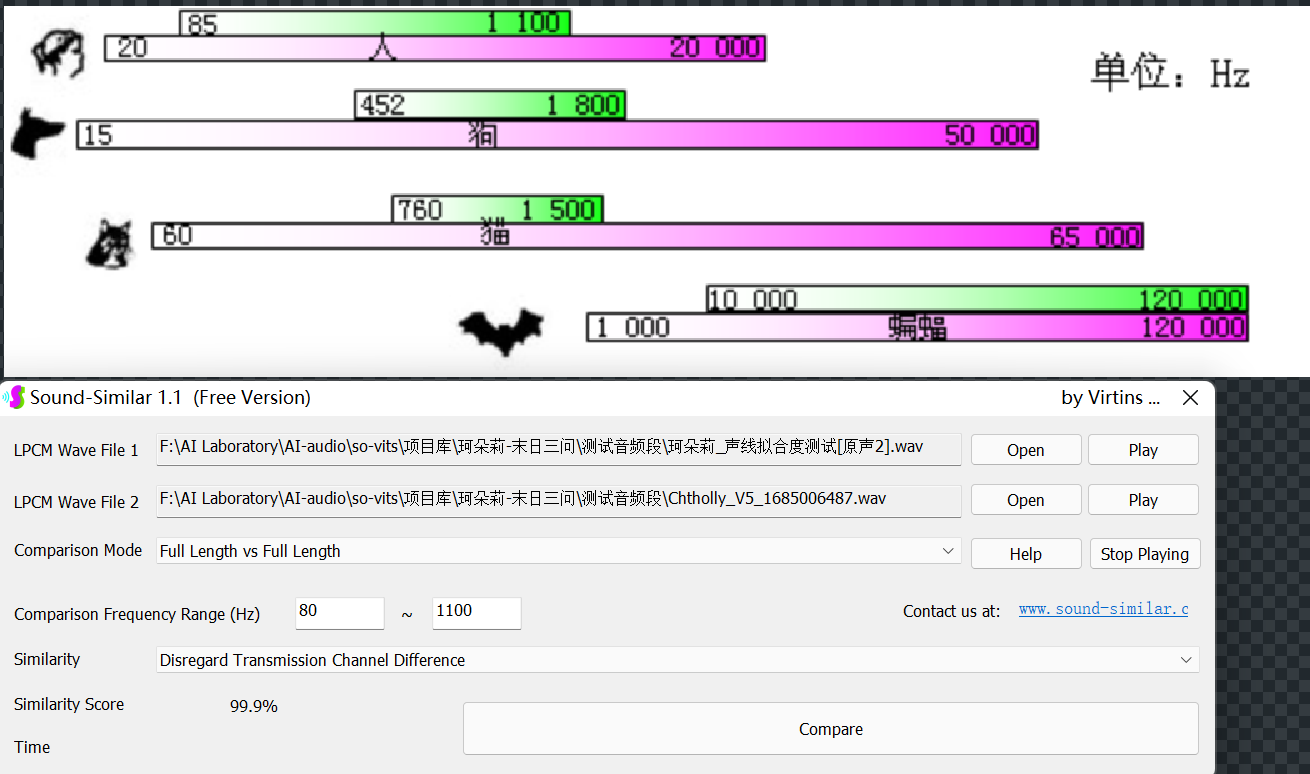
实验结论
优化数据集后,模型在60%的情况下难以分辨与人类声音的区别,但多语种训练会导致模型失衡,训练步数不宜过多。